Sınıflandırma problemlerini çözmekten bahsedildiğinde, lojistik regresyon akla gelen ilk denetimli öğrenme tipi algoritma olmalıdır ve birçok veri bilimci ve istatistikçi tarafından yaygın olarak kullanılmaktadır.
Lojistik regresyon, temel, güçlü ve uygulaması kolay bir tekniktir. Daha da önemlisi, bu temel teorik kavramları anlamak, derin öğrenmeyi kavramanın ayrılmaz bir parçasıdır. Bu nedenle, makine öğrenimi konusunda uzmanlaşmak isteyen herkesin, lojistik regresyon konusunda güçlü bir temel edinmiş olması gereklidir.
Lojistik Regresyon Nedir?
Lojistik regresyon, kategorik bir bağımlı değişkenin olasılığını tahmin etmek için kullanılan denetimli bir makine öğrenimi sınıflandırma algoritmasıdır. Bağımlı değişken, ikili sınıflandırıcı (regresyonda değil) olarak kullanılan 1 (evet/doğru) veya 0 (hayır/yanlış) olarak kodlanmış verileri içeren ikili bir değişkendir. Lojistik regresyon, sürekli ve ayrık değişkenler ve doğrusal olmayan özellikler dahil olmak üzere çok sayıda özellikten yararlanabilir. Lojistik regresyonda Sigmoid (diğer adıyla Lojistik) fonksiyonu kullanılır.
Bulutistan hizmetlerinin detaylarına ulaşmak için tıklayınız.
Lojistik Regresyon Nasıl Çalışır?
Lojistik regresyon, doğrusal regresyondan daha karmaşık bir maliyet fonksiyonu kullanır, bu maliyet fonksiyonu doğrusal bir fonksiyon yerine Sigmoid fonksiyon veya lojistik fonksiyon olarak da bilinir.
Lojistik regresyon hipotezi, maliyet fonksiyonunu 0 ile 1 arasında sınırlama eğilimindedir. Bu nedenle doğrusal fonksiyonlar, lojistik regresyon hipotezine göre mümkün olmayan 1’den büyük veya 0’dan küçük bir değere sahip olabileceğinden bunu temsil etmekte başarısız olur.
Sigmoid fonksiyonu herhangi bir gerçek değeri 0 ile 1 arasında başka bir değere eşler. Makine öğreniminde, tahminleri olasılıklara eşlemek için sigmoid kullanılır.
Lojistik Regresyon İçin Modeller
1. Binomial lojistik regresyon
Lojistik ve doğrusal regresyon, GLM (Genelleştirilmiş Doğrusal Model) adı verilen aynı model ailesine aittir: her iki durumda da bir olay, açıklayıcı değişkenlerin doğrusal bir kombinasyonuna bağlıdır.
Doğrusal regresyon için bağımlı değişken, μ’nün açıklayıcı değişkenlerin doğrusal bir fonksiyonu olduğu N(μ,σ) normal dağılımını takip eder. Lojistik regresyon için, yanıt değişkeni olarak da adlandırılan bağımlı değişken, deney bir kez tekrarlandığında p parametresinin Bernoulli dağılımını (p, bir olayın meydana gelme ortalama olasılığıdır) veya deney nn kez tekrarlanırsa (örneğin nn hastaya aynı doz verilirse) Binom(n,p) dağılımını izler. Olasılık parametresi p burada açıklayıcı değişkenlerin doğrusal bir kombinasyonunun bir fonksiyonudur.
p olasılığını açıklayıcı değişkenlere bağlamak için kullanılan en yaygın fonksiyonlar lojistik fonksiyon (Logit modeline atıfta bulunuyoruz) ve standart normal dağılım fonksiyonudur (Probit modeli). Bu fonksiyonların her ikisi de mükemmel simetrik ve sigmoiddir: XLSTAT iki farklı fonksiyon daha sunar: üst asimptota daha yakın olan tamamlayıcı Log-log fonksiyonu ve tam tersine apsis eksenine daha yakın olan Gompertz fonksiyonu.
Çoğu yazılımda, model parametreleri için güven aralıklarının hesaplanması, parametrelerin normal dağıldığı varsayılarak doğrusal regresyonda olduğu gibidir. XLSTAT ayrıca alternatif “Olabilirlik oranı” yöntemini de sunmaktadır (Venzon ve Moolgavkar, 1988). Bu yöntem, parametrelerin normal dağıldığı varsayımını gerektirmediği için daha güvenilirdir. Ancak iteratif olduğundan hesaplamaları yavaşlatabilir.
2. Multinominal lojistik regresyon
Multinominal lojistik regresyonun temel prensibi, bir değişkenin J farklı kategorisini (değişkenin J kategorisi) açıklayıcı değişkenlerin bir fonksiyonu olarak açıklamak veya tahmin etmektir. Bu nedenle, daha önce ele alınan binom regresyon durumu, J=2 olduğu özel bir durumu temsil eder.
Bu noktada multinominal model çerçevesinde, bir kontrol kategorisi seçilmelidir. Temel olarak, “temel” veya “klasik” veya “normal” duruma karşılık gelen seçilir. Tahmin edilen katsayılar bu kontrol kategorisine göre yorumlanır.
XLSTAT tarafından bir olayın meydana gelme olasılığını açıklayıcı değişkenlerle ilişkilendirmek için önerilen model, binom durumu için önerilen dört modelden biri olan logit modelidir.
Doğrusal regresyonun aksine kesin bir analitik çözüm mevcut değildir. XLSTAT, iteratif olarak bir çözüm bulmak için Newton-Raphson algoritmasını kullanır.
3. Sıralı lojistik regresyon
Sıralı lojistik regresyonun temel prensibi, açıklayıcı değişkenlerin doğrusal bir kombinasyonunun bir fonksiyonu olarak J sıralı alternatif değer alabilen (sadece sıra önemlidir, farklılıklar değil) bir değişkeni açıklamak veya tahmin etmektir. Binom lojistik regresyon ise J=2 olduğu duruma karşılık gelen sıralı lojistik regresyonun özel bir durumunu temsil eder.
XLSTAT, açıklayıcı değişkenler göz önüne alındığında kategorilere atanma olasılıklarını hesaplamak için iki alternatif modelin kullanılmasını mümkün kılar: logit modeli ve probit modeli.
Doğrusal regresyonun aksine kesin bir analitik çözüm mevcut değildir. Bu nedenle iteratif bir algoritma kullanmak gerekir. XLSTAT bir Newton-Raphson algoritması kullanır.
Lojistik Regresyon Ne Zaman Kullanılır?
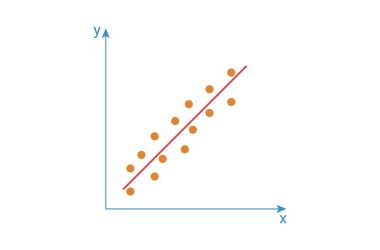
Lojistik regresyon, girdinin doğrusal bir sınırla “iki bölgeye” ayrılması gerektiğinde kullanılır. Veri noktaları gösterildiği gibi doğrusal bir çizgi kullanılarak ayrılır.
Kategori sayısına bağlı olarak lojistik regresyon şu şekilde sınıflandırılabilir:
- binom: Hedef değişken sadece 2 olası tipe sahip olabilir: “0” veya “1”; bunlar “kazanma “ya karşı “kaybetme “yi, “geçme “ye karşı “başarısız olma “yı, “ölü “ye karşı “canlı “yı vb. temsil edebilir.
- multinomial: Hedef değişken, “hastalık A” vs “hastalık B” vs “hastalık C” gibi sıralanmamış (yani türlerin niceliksel önemi yoktur) 3 veya daha fazla olası türe sahip olabilir.
- ordinal: sıralı kategorilere sahip hedef değişkenlerle ilgilenir. Örneğin, bir test puanı “çok zayıf”, “zayıf”, “iyi”, “çok iyi” olarak kategorize edilebilir. Burada her kategoriye 0, 1, 2, 3 gibi bir puan verilebilir.
Lojistik regresyonun en basit şeklini, yani binom lojistik regresyonunu inceleyecek olursak, bir sınıflandırma problemini çözerken, yani y değişkeni yalnızca iki değer aldığında kullanılabilir. Böyle bir değişkenin “ikili” veya “dikotom” değişken olduğu söylenir. “İkili” temel olarak evet/hayır, kusurlu/kusursuz, başarılı/başarısız gibi iki kategori anlamına gelir. “İkili” ise 0’ları ve 1’leri ifade eder.
Farklı lojistik regresyonların doğru kullanımı, verilerle ilgili sorunları çözmek için bir zorunluluktur ve veri bilimi sertifikası alırken öğrendiğiniz istatistiksel beceriler, seçenekleri daraltmak için kullanışlıdır.
Doğrusal vs Lojistik Regresyon
Doğrusal regresyon denkleminde hedef olarak sürekli değişkenler kullanılırken, lojistik regresyon modelinde hedef kesikli bir değişken veya ikili bir değerdir. Doğrusal regresyon için öngörülen değer, hedef değişkenlerin ortalamasıdır. Tahmin edilen değer ise, hedef değişkenlerin olasılığıdır.
| Doğrusal Regresyon | Lojistik Regresyon | |
| Sonuç | Doğrusal regresyonda sonuç (bağımlı değişken) süreklidir. Sonsuz sayıda olası değerden herhangi birine sahip olabilir. | Lojistik regresyonda, sonuç (bağımlı değişken) yalnızca sınırlı sayıda olası değere sahiptir. |
| Bağımlı değişken | Doğrusal regresyon, yanıt değişkeniniz sürekli olduğunda kullanılır. Örneğin, kilo, boy, çalışma saati sayısı vb. | Lojistik regresyon, yanıt değişkeni kategorik yapıda olduğunda kullanılır. Örneğin, evet/hayır, doğru/yanlış, kırmızı/yeşil/mavi, 1./2./3./4. vb. |
| Bağımsız değişken | Doğrusal regresyonda, bağımsız değişkenler birbirleriyle ilişkili olabilir. | Lojistik regresyonda, bağımsız değişkenler birbirleriyle ilişkili olmamalıdır. (çoklu doğrusallık yok) |
| Denklem | Doğrusal regresyon, Y = mX + C şeklinde bir denklem verir, bu da 1. dereceden denklem anlamına gelir. | Lojistik regresyon, Y = eX + e-X şeklinde bir denklem verir. |
| Katsayı yorumu | Doğrusal regresyonda, bağımsız değişkenlerin katsayı yorumu oldukça basittir (yani, diğer tüm değişkenler sabit tutulduğunda, bu değişkendeki bir birimlik artışla, bağımlı değişkenin xxx kadar artması/azalması beklenir). | Lojistik regresyonda, kullandığınız aileye (binom, Poisson, vb.) ve bağlantıya (log, logit, ters-log, vb.) bağlı olarak yorumlama farklıdır. |
| Hata minimizasyon tekniği | Doğrusal regresyon, hataları en aza indirmek ve mümkün olan en iyi uyuma ulaşmak için sıradan en küçük kareler yöntemini kullanırken, lojistik regresyon çözüme ulaşmak için maksimum olabilirlik yöntemini kullanır. | Lojistik regresyon bunun tam tersidir. Lojistik kayıp fonksiyonunun kullanılması, büyük hataların asimptotik bir sabite kadar cezalandırılmasına neden olur. |
Lojistik Regresyonun Avantajları ve Dezavantajları
Doğrusal regresyon modelinin avantaj ve dezavantajlarının birçoğu lojistik regresyon modeli için de geçerlidir. Lojistik regresyon birçok kişi tarafından çeşitli problem türlerini çözmek için yaygın olarak kullanılmasına rağmen, çeşitli sınırlamaları nedeniyle performansını koruyamamakta ve diğer tahmin modelleri daha iyi tahmin sonuçları sağlamaktadır.
Avantajları
- Lojistik regresyon modeli yalnızca bir sınıflandırma modeli olarak hareket etmekle kalmaz, aynı zamanda size olasılıkları da verir. Bu, yalnızca nihai sınıflandırmayı sağlayabilen diğer modellere göre büyük bir avantajdır. Bir örneğin bir sınıf için %51’e kıyasla %99 olasılığa sahip olduğunu bilmek büyük bir fark yaratır. Lojistik regresyon, veri kümesi doğrusal olarak ayrılabilir olduğunda iyi performans gösterir.
- Modeller matematiksel olarak diğer makine öğrenimi modellerinden daha az karmaşıktır ve bu nedenle makine öğrenimi bağlamında çok kullanışlıdır. Böylece, derinlemesine makine öğrenimi uzmanlığınız olmasa bile lojistik regresyon kullanarak verimli makine öğrenimi modelleri oluşturabilir, eğitebilir ve dağıtabilirsiniz.
- Lojistik regresyon yalnızca bir tahmin edicinin (katsayı büyüklüğü) ne kadar alakalı olduğunun bir ölçüsünü vermekle kalmaz, aynı zamanda ilişkinin yönünü de (pozitif veya negatif) verir. Lojistik regresyonun uygulanmasının, yorumlanmasının daha kolay ve eğitilmesinin çok verimli olduğunu gözlemlenmektedir.
- Büyük veri setlerini yüksek hızda işler, çünkü bellek ve işlem gücü açısından daha az hesaplama kapasitesi gerektirir. Bu da onları karmaşık makine öğrenimi projeleri üzerinde çalışan ve hızlı kazanç elde etmek isteyen programcılar için ideal hale getirir.
- Analiz, programcılara dahili yazılım süreçlerinde diğer veri analizi tekniklerine göre daha fazla görünürlük sağlar. Denklem kullanılarak yapılan hesaplamalar daha az karmaşık olduğu için sorun giderme daha kolay hale gelir.
Dezavantajları
- Lojistik regresyon tam ayırma sorunu yaşayabilir. İki sınıfı mükemmel şekilde ayıracak bir özellik varsa, lojistik regresyon modeli artık eğitilemez. Çünkü bu özellik için ağırlık yakınsanamaz, optimum ağırlık sonsuz olur. Bu gerçekten biraz talihsiz bir durumdur, çünkü böyle bir özellik oldukça çok kullanışlıdır. Ancak her iki sınıfı da ayıran basit bir kuralınız varsa, makine öğrenimine ihtiyacınız yoktur. Tam ayırma sorunu, ağırlıkların cezalandırılması veya ağırlıkların önceden olasılık dağılımının tanımlanmasıyla çözülebilir.
- Lojistik regresyon, aşırı uyuma karşı daha az eğilimlidir, ancak yüksek boyutlu veri kümelerinde aşırı uyum sorunlarına yol açabilir. Bu tür senaryolarda, aşırı uyumu önlemek için düzenleme tekniklerini dikkate almak önemlidir.
Lojistik Regresyon Nerede Kullanılır?
Aşağıda lojistik regresyonun kullanıldığı bazı gerçek dünya senaryolarını bulabilirsiniz:
İkili bir olayın gerçekleşme olasılığını hesaplamak, bir e-posta’nın spam olup olmadığını veya bir kredi kartı işleminin dolandırıcılık olup olmadığını sınıflandırmamıza yardımcı olabilir. Tıbbi bağlamda, bir tümörün kötü huylu olup olmadığı gibi bir sağlık sonucunu tahmin etmek için kullanılabilir.
Lojistik regresyonun her türlü evet/hayır sonucunun olasılığını tahmin ettiğini görebilirsiniz. Model, tahminlerde bulunarak veri bilimcilerin riskleri en aza indirmek, harcamaları optimize etmek ve kârı en üst düzeye çıkarmak için bilinçli iş kararları almalarına yardımcı olur.
Örneğin, bir kredi kartı şirketi başvuran her kişiye kart vermez. Kredi kartı için uygun olabilecek müşterileri kategorize etmek için bir model kullanarak kişinin “temerrüde düşeceği” ya da “temerrüde düşmeyeceği” gibi iki olası ikili sonucu analiz etmeleri gerekir.
Makine Öğreniminde Lojistik Regresyon Nedir?
Lojistik regresyon, yapay zeka ve makine öğreniminde (AI/ML) çok önemli bir tekniktir. Makine Öğrenimi (ML) modelleri, karmaşık veri işleme görevlerini manuel müdahale olmadan gerçekleştirmek için ayarlayabileceğiniz ve eğitebileceğiniz yazılım programlarıdır. Lojistik regresyon kullanılarak oluşturulan ML modelleri, iş verilerinden eyleme geçirilebilir içgörüler sağlayabilir ve operasyonel giderleri azaltmak ve üretkenliği artırmak için tahmine dayalı analiz yapabilir.
Bulutistan hizmetlerinin detaylarına ulaşmak için tıklayınız.
Makine Öğreniminde Lojistik Regresyon Uygulamaları
Lojistik regresyon, makine öğreniminde aşağıdakiler de dahil olmak üzere geniş bir uygulama alanına sahiptir:
1. Müşteri Kaybını Tahmin Etme
Müşteri kaybı birçok sektörde yaygın bir sorundur ve lojistik regresyon hangi müşterilerin ayrılma olasılığının yüksek olduğunu tahmin etmek için kullanılabilir. Demografik bilgiler, satın alma geçmişi ve müşteri hizmetleri etkileşimleri gibi müşteri verilerini analiz ederek lojistik regresyon, müşteri kaybıyla en güçlü şekilde ilişkili faktörleri belirleyebilir ve hangi müşterilerin ayrılma riskinin en yüksek olduğunu tahmin edebilir.
2. Kredi Puanlaması
Lojistik regresyon, bir kredinin temerrüde düşme olasılığını tahmin etmek için kredi puanlamasında da yaygın olarak kullanılır. Lojistik regresyon, kredi geçmişini, geliri ve diğer faktörleri analiz ederek, temerrütle en güçlü şekilde ilişkili olan faktörleri belirleyebilir ve hangi borçluların temerrüde düşme riskinin en yüksek olduğunu tahmin edebilir.
3. Tıbbi Teşhis
Lojistik regresyon, bir hastanın semptomlarına ve tıbbi geçmişine dayanarak belirli bir hastalığa sahip olma olasılığını tahmin etmek için tıbbi tanıda kullanılabilir. Lojistik regresyon, hasta verilerini analiz ederek hastalıkla en güçlü şekilde ilişkili olan faktörleri belirleyebilir ve hangi hastaların hastalığa yakalanma riskinin en yüksek olduğunu tahmin edebilir.
4. Dolandırıcılık Tespiti
Lojistik regresyon, işlem tutarı, konum ve zaman gibi çeşitli faktörlere dayalı olarak bir işlemin hileli olma olasılığını tahmin etmek için dolandırıcılık tespitinde kullanılabilir. Lojistik regresyon, işlem verilerini analiz ederek dolandırıcılıkla en güçlü şekilde ilişkili faktörleri belirleyebilir ve hangi işlemlerin dolandırıcılık riskinin en yüksek olduğunu tahmin edebilir.